| |
Python Tutorial
Python OOPs
Python MySQL
Python MongoDB
Python SQLite
Python Questions
Plotly
Python Tkinter (GUI)
Python Web Blocker
Python MCQ
Related Tutorials
Python Programs

Boyer Moore Algorithm for Pattern Searching using PythonThe Boyer Moore Algorithm is the most efficient in pattern matching algorithms. Pattern searching methods display search results when looking at a string in a notepad/word file, web browser, or database. A common pattern searching technique is the Boyer Moore String Search technique, with practical applications. Strings search methods quicker than O(n) usually need some preprocessing of the text, which can be computationally expensive if done frequently or memory-intensive if the text is extensive. Boyer Moore requires that the pattern being sought be pre-processed. This algorithm starts with preprocessing the string we want to search. The information we get from the preprocessing is used for further steps in the search algorithm. The main property of this algorithm is to match the tail portion of the sequence instead of the head and skip down the text in multiple character jumps rather than checking every letter in the text. Problem StatementA string is given as str[0….s - 1] and a pattern string as ptn[0….p-1], where s is the string length, and p is the length of the pattern; we need to make a function that will print all the occurrence of the pattern string in the text string. We can assume that the length of the text string is more than the length of the pattern string. Let's understand the problem statement with a few examples. Example 1: Example 2: 
Explanation: An immutable data type used to store the characters and multiple sequences is known as a string. If we look at the examples, we have started from the beginning index to search for the pattern. In this first example, we started to search the pattern "TEST" from the index 0 and got the pattern at index 6 and then 18. Similarly, we tried to find the pattern "ABBA" in the second example and started searching it from the first position. We got the pattern first at the 4th index and then at the 11th index. We will use the Boyer Moore algorithm to search patterns in strings, where two pointers are assigned, which searches the pattern in the string. The pointer is assigned at the 0th index of the string and the character string. This algorithm searches the pattern from the last character. Then, the pattern is compared with the text string from its current position, starting from the rightmost character. When a character fails to match, the Boyer-Moore algorithm moves the characters simultaneously in two ways:
Bad Character HeuristicsWhen the algorithm fails to find the pattern in the string, it gives two different cases:
In these situations, the mismatched character is called a bad character. When a mismatched character is discovered, we move the pattern until it matches the characters of the string. For instance, we are searching the pattern PCERST in the string ABPRPXCPREDFT. When we compared the pattern string with the text string, we found a mismatch between P, the character of the string (the bad character), and E, the character of the pattern. Then, we will shift the pattern string until the character P of the pattern string matches the character P of the text string. Explanation: We started to search for the pattern in the text string from the index 0 and found that the first character is not matched with the pattern character. Then, we shifted the pattern to match the string text.
To understand this situation, let's take an example: We need to search the pattern string PCERST in the string ABPRPXCPREDFT. We will compare the pattern from right to left. 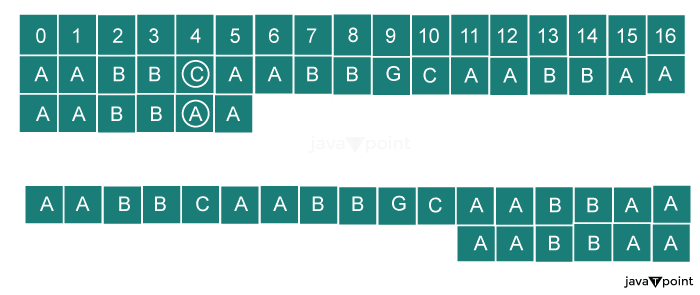
Implementation for the bad character heuristics:Code: Output: The Pattern found at index: 7 Complexity Analysis of Bad Character Heuristics In this approach, we have traversed the pattern for each part of the text string. Time Complexity The time complexity of this approach is O (n x m), where n is the length of the text and m is the length of the pattern. Space Complexity No extra space is being used for the preprocessing of the array. Thus, the space complexity is (O (1)). Good Suffix HeuristicsA different approach to searching the pattern with the Boyer-Moore algorithm is first to discover the good suffix and then analyze it. The fundamental idea is to align the overlapping regions of the pattern and the text string together to shift more effectively when a mismatch occurs. Let's understand this situation with the help of an example. Take a pattern and start searching from the right side. Assume that a part of the pattern string is found. We will search till a mismatch is found. The matched pattern or the part of the pattern that matches the text string is called a Good String. Any mismatch in the text means that the current location is not the starting location of the pattern string. Now, we will shift the pattern to the next location for searching. The good suffix can be used for shifting the pattern. There are two situations in which we use a good suffix: 1. The position of the good suffix is different in the pattern: For example, the text string is AABBCAABBGCAABBAA, and the pattern string is AABBAA; we can see that the good string (a portion of the pattern string is matched to the text string) is present at different positions. We will shift the good suffix such that it is aligned to the text and the pattern text matches the text string. 2. Some portion of the good suffix is a prefix of the pattern: While searching, we found a mismatch in the pattern, but not the exact match of the good string. If the good suffix is found as the prefix of the pattern, we can shift the suffix to align the pattern with the text string. 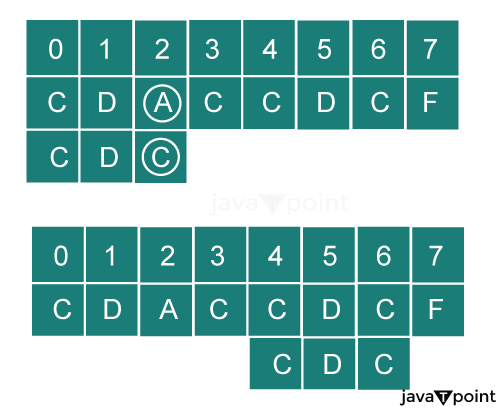
Implementation for the good character heuristics:Code: Output: The Pattern is found at index: 4 The Pattern is found at index: 13 Complexity Analysis of Good Character Heuristics In this method, we have traversed the pattern string and preprocessed the string for the suffix and prefix. Time Complexity The time complexity of this approach is O (m x n), where m is the length of the text and n is the length of the pattern. Space Complexity The space complexity of this approach is [O (n) + O (n)], which is equal to O (m), where m = n + n.
Next TopicCLEAN Tips to IMPROVE Python Functions
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








