Split Single Column into Multiple Columns in PySpark DataFrame
In records evaluation and manipulation responsibilities, it's not unusual to work with tabular facts saved in a dependent format like DataFrames. PySpark, a powerful framework for allotted information processing, gives various functions to carry out complex information modifications efficiently. One common venture is splitting an unmarried column into a couple of columns, which may be performed using PySpark's integrated features.
Introduction to PySpark DataFrame
PySpark DataFrame is a fundamental abstraction within the PySpark library, designed for dispensed records processing and manipulation. It is a vital part of the Apache Spark ecosystem and affords a powerful and green way to paintings with structured information at scale. PySpark DataFrame builds on the abilities of Spark's Resilient Distributed Dataset (RDD) model and extends it to offer a better-degree, tabular records shape just like SQL tables or Pandas DataFrames.
Key Features of PySpark DataFrame:
- Optimization: PySpark DataFrame consists of an optimizer that may push down operations into decrease-level RDDs and optimize question execution plans. This optimization improves overall performance by using decreasing statistics shuffling and minimizing the quantity of data moved across the community.
- Distributed Processing: PySpark DataFrame leverages the allotted computing abilities of Apache Spark. It distributes information throughout a cluster of machines and tactics it in parallel, enabling efficient processing of big datasets.
- Interoperability: PySpark DataFrames seamlessly integrate with other Spark additives, along with Spark SQL for SQL querying and based statistics processing, MLlib for gadget mastering, and Spark Streaming for real-time information processing.
- Schema and Metadata: PySpark DataFrames have a schema, which defines the shape of the statistics, along with column names and statistics types. This schema information is used for numerous optimizations and statistics validation.
- Lazy Evaluation: Similar to Spark RDDs, PySpark DataFrames use lazy evaluation. Transformations on DataFrames are not executed right away however are recorded in a logical execution plan. This permits Spark to optimize the execution plan earlier than actual computation, leading to higher overall performance.
- API Simplicity: PySpark DataFrame gives an excessive-stage, SQL-like API that lets in customers to explicit complex information transformations using a familiar interface. This abstraction makes it simpler for SQL and programming-oriented users to work with records.
Splitting a Column: The Scenario
Consider a situation in which you have a DataFrame with a column containing values that need to be broken up into separate columns. This is common when handling data that has composite values stored within an unmarried subject, including a full call or a date with 12 months, month, and day additives.
In this tutorial, we will stroll through the technique of splitting an unmarried column into multiple columns using PySpark.
Splitting a Column Using PySpark
To cut up a single column into multiple columns, PySpark presents numerous integrated capabilities, with cut up() being the maximum normally used one. The split() characteristic takes two arguments: the column to cut up and the delimiter that separates the values.
Here's a step-through-step manual on how to split a single column into more than one columns in a PySpark DataFrame:
Importing Required Modules:
Creating a SparkSession:
Creating DataFrame:
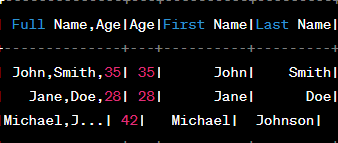
Let's count on you having got a DataFrame named df with a column named "Full Name". We will break up this column into "First Name" and "Last Name" columns.
Using the split() Function:
Now, permit's split the "Full Name" column into "First Name" and "Last Name" columns and the usage of the 'split()' feature.
Displaying the Result:
Whole Code:
Output:

Another Code:
Output:
PySpark DataFrame offers numerous blessings and a few negative aspects, just like any technology. Understanding these professionals and cons assist you to make informed selections approximately whether PySpark DataFrame is the right desire for your records processing and analysis desires.
Advantages of PySpark DataFrame:
- Distributed Processing: PySpark DataFrame is built on Apache Spark, which enables distributed processing across a cluster of machines. This results in big overall performance upgrades for large-scale statistics processing tasks.
- Ease of Use: The DataFrame API is user-pleasant and provides a familiar SQL-like interface for statistics manipulation. This makes it reachable to both SQL and programming-oriented users.
- Parallel Processing: DataFrames permit parallel processing of statistics, leveraging the total capabilities of a cluster. This speeds up information evaluation and reduces processing time.
- Lazy Evaluation: Like other Spark additives, PySpark DataFrame operations are lazily evaluated, which lets Spark optimize the execution plan earlier than actual computation. This can result in higher performance and resource usage.
- Optimization: PySpark DataFrame consists of a Catalyst optimizer that optimizes query execution plans. This optimization can cause efficient question processing through minimizing statistics shuffling and reducing unnecessary computations.
- Schema and Type Safety: PySpark DataFrames have a schema, ensuring that the records adhere to a described shape. This adds a layer of information validation and type protection.
- Integration: PySpark DataFrame seamlessly integrates with different Spark additives together with Spark SQL, MLlib, and Spark Streaming, providing a comprehensive platform for various fact processing obligations.
Disadvantages of PySpark DataFrame:
- Memory Overhead: DataFrames introduce a few memory overheads because of the additional metadata and optimization systems. This can affect the memory utilization for extremely small datasets.
- Learning Curve: While the DataFrame API is designed to be user-pleasant, there's nevertheless a getting to know curve, in particular for users who are new to dispersed computing ideas.
- Limited Expressiveness: While the DataFrame API is flexible, it may not cowl all the operations that may be performed with decrease-stage RDD changes. In a few instances, customers might want to revert to RDDs for unique custom operations.
- Serialization Overhead: DataFrame operations contain serialization and deserialization of statistics that can add overhead, specifically for first-rate-grained operations.
- Debugging Challenges: Debugging allotted structures may be extra difficult as compared to single-machine answers. Identifying issues that rise up in complex differences and optimizations can require extra expertise.
- Complexity of Setup: Setting up a Spark cluster and configuring resources may be more complex than the usage of a single-gadget solution. This complexity increases whilst coping with larger clusters.
|

 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now








